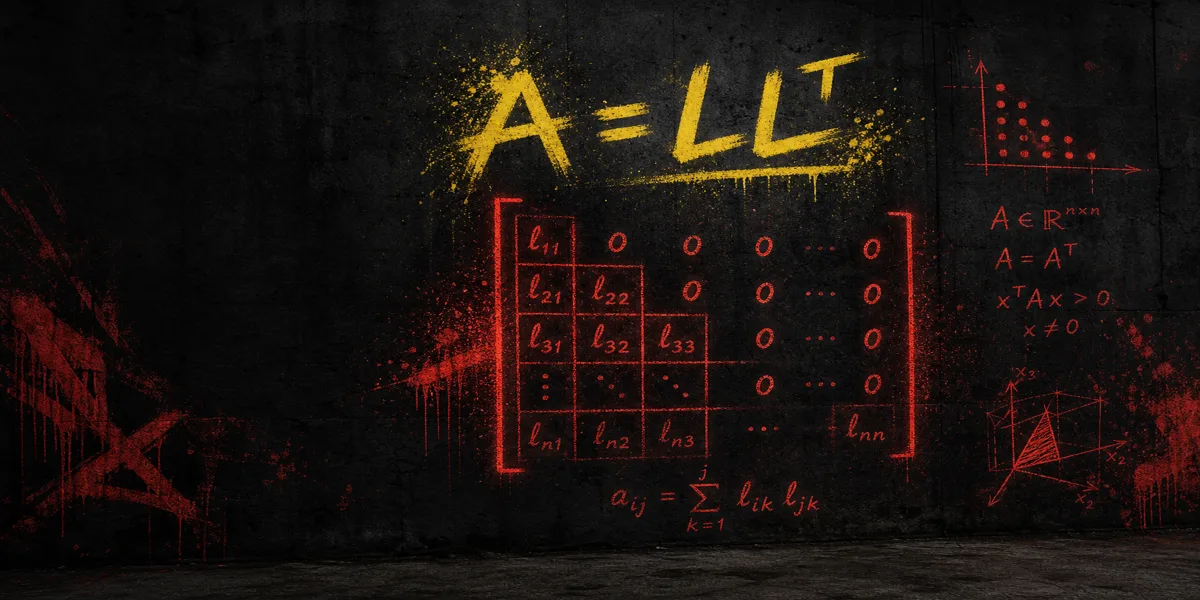
Quick answer
In ML, Cholesky often factors SPD matrices (covariances, kernels) to sample Gaussians, solve linear systems, and stabilize quadratic forms.
Formula
- Σ = L Lᵀ for covariance Σ
- Sample z ~ N(0,I), then Lz + μ
- Requires SPD (or regularized SPD)
Introduction
Before diving into large models, sanity-check small covariance matrices on the Cholesky Decomposition Calculator to see whether a matrix is numerically SPD.
Libraries hide L behind calls like cholesky or chol, but the same A = L Lᵀ logic drives sampling and log-determinants.
Review positive definite matrices when eigenvalue clipping or jitter appears in your pipeline, and numerical analysis notes when rounding breaks factorization.
Where ML meets Cholesky
Multivariate Gaussian sampling: If Σ = L Lᵀ, then μ + Lz with standard normal z produces covariance Σ.
Gaussian processes: Kernel matrices on finite point sets must be SPD (or regularized) before Cholesky-based inference.
Some optimization routines use Cholesky of Hessian approximations when curvature is modeled as SPD.
Log-determinants for likelihoods often use sum of logs of diagonal entries of L rather than explicit eigenvalues.
When data are scarce, empirical covariance matrices may be nearly singular; practitioners add λI before Cholesky.
Understanding failure messages from a teaching calculator mirrors debugging chol failures in NumPy or similar tools.
Formulas ML code relies on
- Σ = L Lᵀ
- x ~ N(μ, Σ) via x = μ + L z
- log det Σ = 2 sum log L[i,i]
The sampling formula is why SPD matters: if L is not real, the distribution model is wrong for that matrix.
Log-determinant from L diagonals appears in Gaussian log-likelihoods and some loss terms.
Regularization Σ + εI is the standard fix when eigenvalues dip below zero numerically.
ML workflow connections
- Build or load Σ. Ensure symmetry numerically by averaging with the transpose if needed.
- Regularize if needed. Add a small multiple of the identity when eigenvalues are tiny.
- Factor Σ = L Lᵀ. Use library Cholesky or the teaching calculator on small cases.
- Sample or solve. Apply L in sampling or triangular solves.
- Debug failures. Map library errors back to SPD violations.
Tiny covariance example
Let Σ = [[1.0, 0.5], [0.5, 1.0]]. Cholesky gives L with positive diagonals; sampling Lz produces correlated features.
If you remove regularization from a rank-deficient empirical Σ, Cholesky fails, matching library errors you may have seen.
Enter Σ in 2×2 mode on the site to compare L with a manual computation from the formula article.