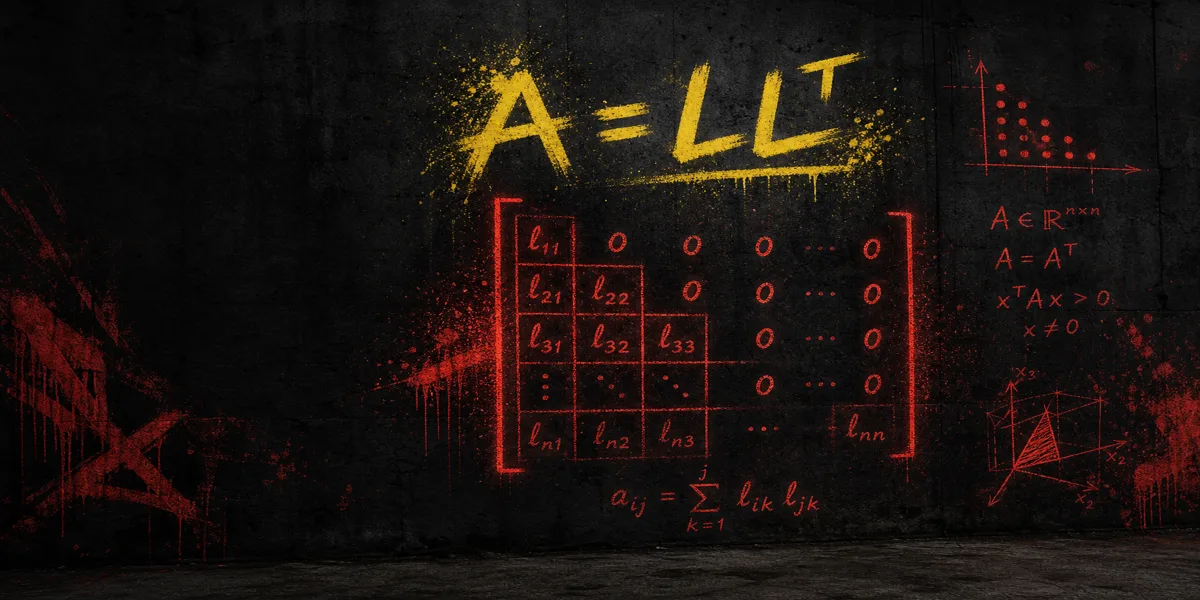
Quick answer
Use Cholesky when A is symmetric positive definite for a fast, structured A = L Lᵀ factorization. Use LU (with pivoting) for general square systems where Cholesky does not apply.
Formula
- Cholesky: A = L Lᵀ (SPD)
- LU: PA = LU (general square, pivoting)
Introduction
If you already know A is SPD, start with the Cholesky Decomposition Calculator instead of a generic solver path.
LU is the workhorse for general linear systems. Cholesky is the specialized SPD shortcut that saves time and memory when its assumptions hold.
For algorithm details after this comparison, see Cholesky in numerical analysis and the factorization calculator guide.
Side-by-side differences
Matrix class: Cholesky needs symmetry and positive definiteness. LU targets general nonsingular square matrices with pivoting for stability.
Factors: Cholesky returns one real triangular factor L with A = L Lᵀ. LU returns lower L and upper U with a permutation P when pivoting is used.
Cost: Cholesky costs about n³/3 flops for large n on SPD matrices, similar to LU but with smaller constants because symmetry is exploited.
Stability: For SPD matrices, Cholesky is often the preferred stable choice without pivoting. LU may still need pivoting even when Cholesky would work.
Failure modes: Cholesky fails clearly when a sqrt argument goes negative. LU fails when no pivot can avoid a zero pivot on singular matrices.
When homework gives a symmetric matrix that is not positive definite, LU or LDLᵀ style methods are the teaching point, not Cholesky.
Formulas in comparison
- Cholesky: A = L Lᵀ
- LU: PA = LU
- SPD ⇒ Cholesky diagonal square roots stay real
Do not apply Cholesky formulas to a matrix just because it is symmetric. Positive definiteness is extra structure.
Normal equations A = Rᵀ R with A = Xᵀ X are the classic SPD source where Cholesky beats LU on cost.
If you are unsure, try a small leading-minor test before picking the algorithm.
Choosing a decomposition
- Check symmetry. If not symmetric, LU is the immediate candidate.
- Test SPD if symmetric. Leading minors, eigenvalues, or a Cholesky attempt.
- Pick Cholesky when SPD. Compute L with A = L Lᵀ.
- Otherwise use LU with pivoting. Solve PA = LU x = P b workflows in courses and libraries.
- Document your choice. Exams reward stating assumptions explicitly.
Same matrix, different outcomes
A = [[4, 2], [2, 3]] is SPD. Cholesky gives L with positive diagonals; LU also exists but does extra work.
A = [[1, 2], [2, 1]] is symmetric but not positive definite. Cholesky fails at the sqrt step; LU with pivoting may still factor for solving purposes depending on teaching context.
Reporting which method failed and why separates conceptual understanding from calculator button pressing.